Transforming RAG Efficiency: Tips for Optimizing Retrieval and Generation
Oct 29, 2024 by Md Mesbah Uddin

Table of Contents
- Retrieval Augmented Generation
- Query optimization and Enhancement
- Multi-Query with RAG fusion
- Query decomposition
- Step Back
- HyDE (Hypothetical Document Embeddings)
- Create Your Own AI Agent
Retrieval Augmented Generation
Retrieval Augmented Generation (RAG) is an advanced technique that enhances language models by integrating them with external knowledge bases. RAG addresses a key limitation of language models: their dependence on fixed training datasets, which can lead to outdated or incomplete information. RAG typically has two main components: the retrieval system and the generation system. The retrieval system searches for relevant information, while the generation system utilizes the retrieved information to generate responses.
All new data sources are stored or indexed in a vector database based on content. When a query is received, it is transformed into an embedding, and the RAG retrieval system first searches the knowledge base for relevant information using similarity search. The basic RAG workflow follows this sequence.
 Fig 1: A basic RAG flow from the internet.
Fig 1: A basic RAG flow from the internet.
The retrieval-augmented generation (RAG) method is generally straightforward, but it faces numerous challenges in practical applications that can hinder performance. Here are some key limitations affecting RAG effectiveness:
Diverse and Ambiguous Questions: Users often pose varied and unclear questions, making it difficult for retrieval systems to identify the most relevant documents in the vector database.
Complex, Multi-Part Questions: When questions are intricate and consist of multiple components, retrieval systems may struggle to grasp their full meaning, leading to incomplete answers.
Subjective Questions: Some questions require a nuanced understanding of the documents involved. Traditional RAG systems may fail to retrieve the most relevant information in these cases.
Short Questions with Long Answers: A common challenge arises when users ask concise questions that demand more extensive answers. This mismatch can lead to ineffective similarity matching, resulting in incorrect or irrelevant responses.
Loss of Information During Indexing: When documents are indexed in vector databases, the embedding process often compresses the data, potentially resulting in the loss of critical information.
Chunking Limitations: Many RAG approaches divide documents into chunks, but determining the appropriate chunk size and quantity can be challenging for users. Inadequate chunking may lead to a lack of context necessary for accurate answers.
Handling Varied Question Types: RAG systems must effectively address both "lower-level" questions that reference specific facts and "higher-level" questions that synthesize information across multiple documents. Typical kNN retrieval can struggle with this duality, as it retrieves a limited number of document chunks.
Semantic Compression: Embedding models convert text into fixed-length vector representations to facilitate efficient search and retrieval. However, this compression places significant pressure on a single vector to capture all semantic nuances, and irrelevant or redundant content can dilute the embedding's effectiveness.
These limitations significantly impact RAG performance. To enhance the RAG system, I have identified three main areas where new ideas can be introduced:
- Query Optimization and Enhancement: Improving how queries are formulated and refined to increase relevance and clarity.
- Indexing Improvement and Optimization: Enhancing the way documents are indexed to retain more information and improve retrieval efficiency.
- Retrieval Systems Improvement: Developing better retrieval techniques that can handle diverse question types and complexities more effectively. 4 Generation Improvement: Enhancing the answer generation process to ensure responses are more accurate and contextually appropriate.
In this article, I will discuss only 1st area mentioned in the above which is Query Optimization and Enhancement.
Query optimization and Enhancement
The first input of the RAG method is the user questions. As mentioned, user questions can vary widely in wording in real-world scenarios. The aim of this technique is to refine the question to improve retrieval accuracy and optimize RAG performance. Several techniques can be applied for this purpose:
Multi-Query + RAG Fusion: Ideal for covering multiple perspectives of a question. Decomposition: Useful when a question can be broken down into smaller sub-questions. Step Back: Helpful when a high-level conceptual understanding is needed. HyDE (Hypothetical Document Expansion): Useful for cases where retrieving relevant documents with raw user inputs is challenging.
Multi-Query with RAG fusion
A common challenge is that some questions may be worded in ways that do not align well with document vector embeddings. To address this, we generate multiple variations of each question with different wording using a new LLM, enabling the retrieval system to capture a broader context and find more relevant documents. This allows the system to return multiple documents, which can then be combined to create a comprehensive and accurate answer.
Once multiple queries are generated, a technique called RAG-Fusion can be applied. RAG-Fusion is a search methodology that bridges the gap between traditional search methods and the complex, multidimensional nature of human queries. It builds on the multi-query approach: after generating multiple questions and retrieving multiple relevant documents, RAG-Fusion re-ranks each result. This re-ranking uses Reciprocal Rank Fusion and custom vector score weighting to deliver a thorough, balanced outcome. RAG-Fusion is particularly useful for answering high-level questions that require diverse perspectives.

Fig. 2: An illustrative representation of RAG-Fusion’s working mechanism. Image by author.
Decomposition
Query decomposition is a technique used to break down complex queries into simpler, manageable steps. Each sub-question is answered individually, and then an LLM synthesizes these responses to reason out the final answer based on the answers to each sub-question. This is a very good technique if the questions are complicated and mathematical questions.
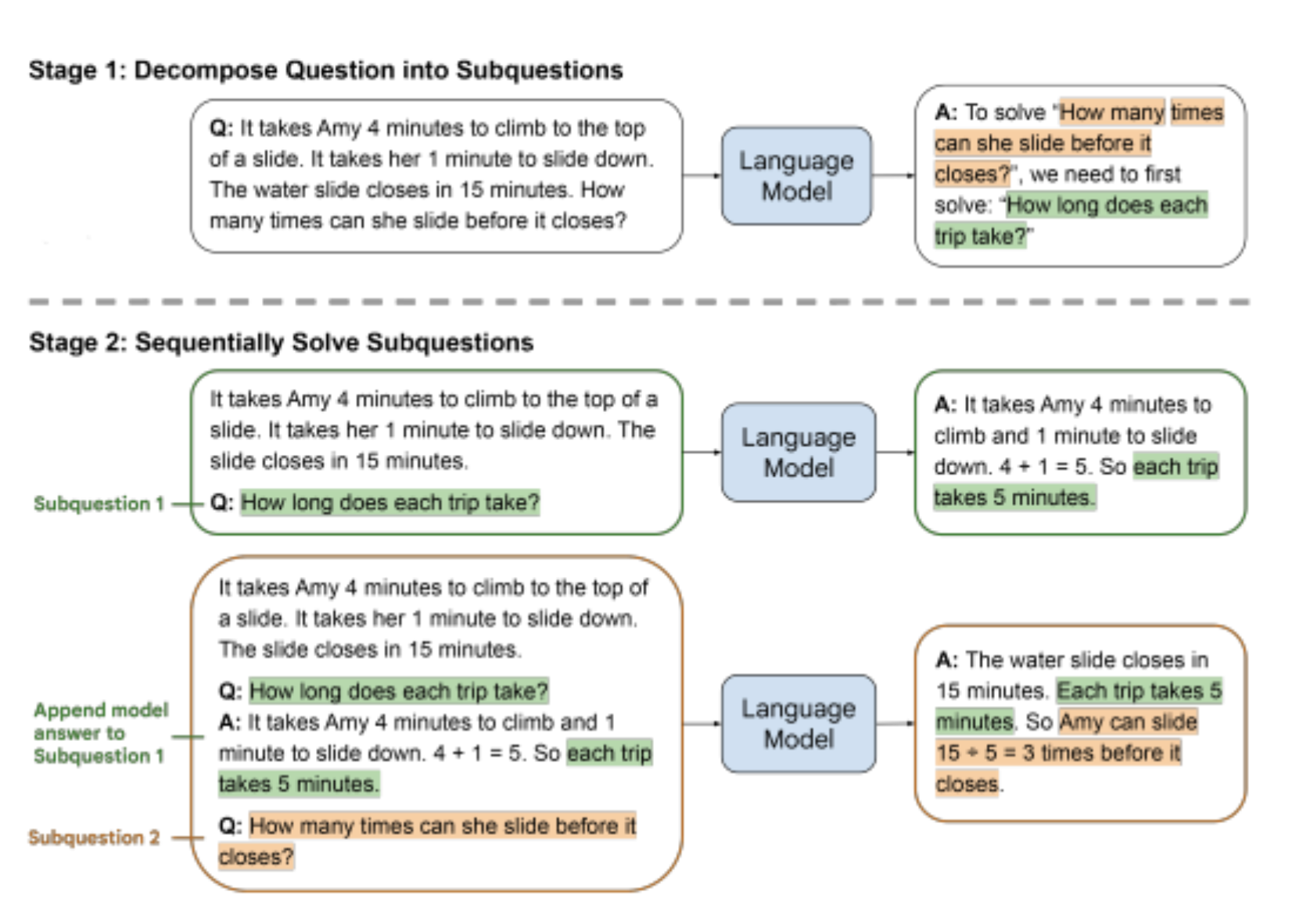
Fig. 3: An illustrative representation of question decomposition by author.
This idea can be more enhanced by applying the Chain-of-Thought Reasoning. This author proposed a IRCoT, a new approach for multi-step QA that interleaves retrieval with steps (sentences) in a CoT, guiding the retrieval with CoT and in turn using retrieved results to improve CoT.

Fig. 4 : IRCoT interleaves chain-of-thought (CoT) generation and knowledge retrieval steps in order to guide the retrieval by CoT and vice-versa. This interleaving allows retrieving more relevant information for later reasoning steps, compared to standard retrieval using solely the question as the query.
Step Back
Google introduced a novel method known as step-back prompting. This technique enhances information retrieval by leveraging chain-of-thought reasoning. It starts with an initial question and formulates a broader, more abstract question that helps lay the groundwork for answering the original query accurately. This approach is particularly beneficial for complex or hypothetical questions where a deeper understanding or background knowledge is essential.

Fig. 5: An illustrative representation of question decomposition by author. Illustration of STEP-BACK PROMPTING with two steps of Abstraction and Reasoning guided by concepts and principles
HyDE (Hypothetical Document Embeddings):
A major challenge in question-answering retrieval-augmented generation (QA RAG) is the disparity in length between short questions and longer answers. The questions are very short, and the answer is expecting a large. This often complicates the similarity matching process, causing the retriever to generate incorrect or irrelevant answers. To address this issue, we can implement HyDE. Rather than directly matching questions with documents, this approach generates hypothetical answers. We then compare the embeddings of these hypothetical answers against those of larger documents, improving the retrieval process and enhancing answer relevance.

Fig. 6: An illustration of the HyDE model by author.
In my next subsequent blog post, I will discuss with other improvement areas.
Create Your Own AI Agent
We created getassisted.ai for building a seamless multi-agent system. You do not need to write any code. The goal is to create an assistant that helps you learn any niche topics. Whether you're a researcher, developer, or student, our platform offers a powerful environment for exploring the possibilities of multi-agent systems. Here is the link to explore some of the: assistants created by our users.